17 авг. 2023 г.
Кажется, что сегодня, когда нам нужно использовать очередь сообщений в проекте, Kafka является идеальным продуктом. Однако, если учитывать конкретные требования, это не всегда лучший выбор.

Давайте снова воспользуемся нашим примером со Starbucks. Существуют два наиболее важных требования:
- асинхронная обработка, чтобы кассир мог принять следующий заказ, не дожидаясь завершения предыдущей задачи;
- сохраняемость, чтобы в случае возникновения проблем не пропустить какой-либо заказ клиента.
Порядок сообщений в данном случае не имеет большого значения, поскольку баристы часто готовят порции одного и того же напитка. Масштабируемость также не так важна, поскольку очереди ограничены каждой кофейней Starbucks.
Очереди Starbucks можно реализовать в таблице базы данных. На схеме ниже показано, как это работает:
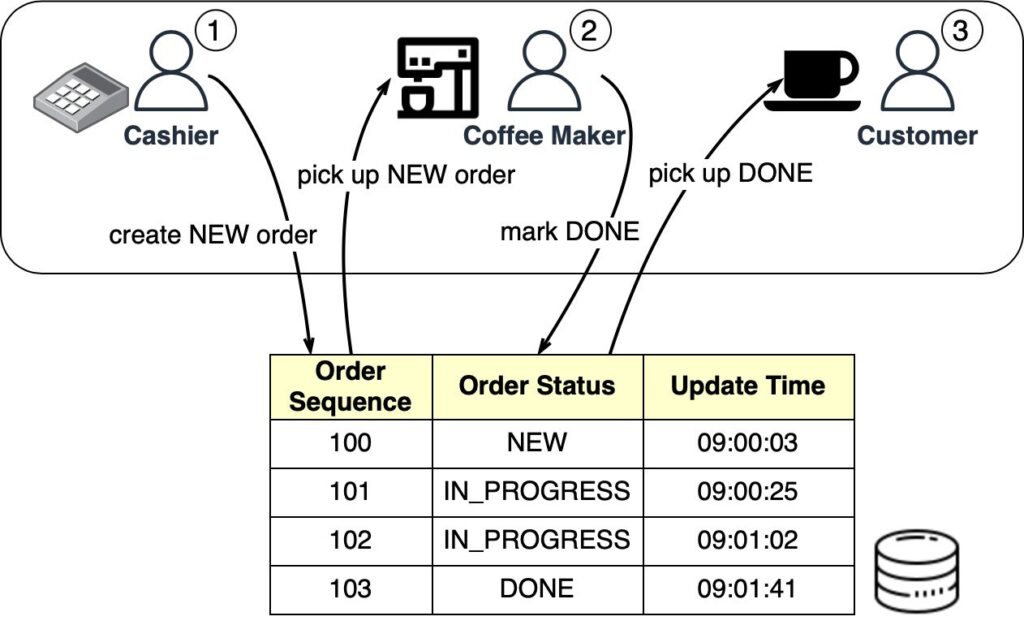
Когда кассир принимает заказ, в очереди с базой данных создается новый заказ. Затем кассир может принять еще один заказ, в то время как бариста группирует новые заказы по порциям. Как только заказ будет выполнен, бариста пометит такой заказ в базе данных как выполненный. Затем клиент забирает свой кофе у стойки.
В конце каждого дня можно запускать служебные действия для удаления выполненных заказов (то есть заказов со статусом «ГОТОВО»).
В случае Starbucks простая очередь с базой данных отвечает требованиям и не требует использования Kafka. Таблица заказов с операциями CRUD (вставка, выборка, обновление и удаление данных) работает нормально.
Очередь в Redis
Очередь сообщений с базой данных по-прежнему требует работ по разработке для создания таблицы очереди и чтения/записи из нее. Для небольшого стартапа с ограниченным бюджетом, в котором уже используется Redis для кэширования, Redis также может выполнять функцию очереди сообщений.
Существует три способа использовать Redis в качестве очереди сообщений
- Издатель — подписчик
- Список
- Поток
На схеме ниже показано, как это работает.
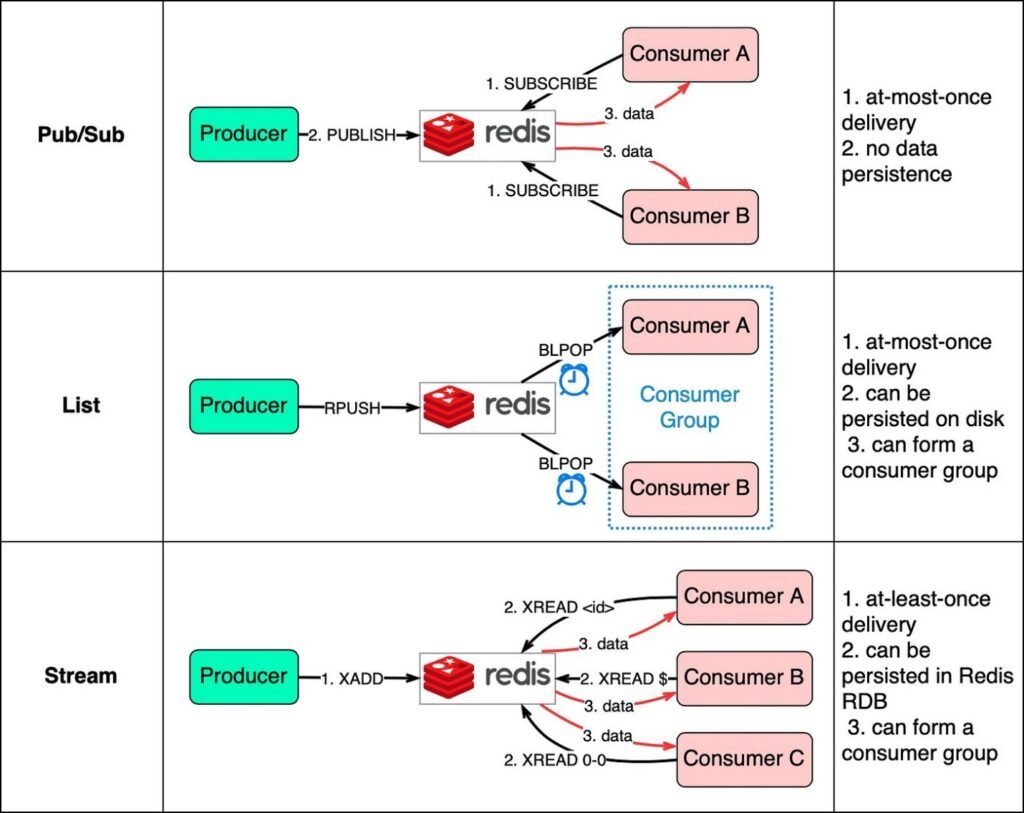
Шаблон «издатель — подписчик» удобен для использования, но имеет некоторые ограничения на доставку данных. Пользователь подписывается на ключ и получает данные, когда издатель публикует данные для этого ключа. Ограничение состоит в том, что данные доставляются только один раз. Если пользователь отключился и не получил опубликованные данные, эти данные теряются. Кроме того, данные не сохраняются на диске. В случае сбоя Redis все данные, отправляемые по шаблону «издатель — подписчик», будут потеряны. Шаблон «издатель — подписчик» подходит для мониторинга показателей, где допустима потеря некоторых данных.
Структура данных списка в Redis может создавать очередь FIFO (первым вошел — первым вышел). Пользователь использует BLPOP для ожидания сообщений в режиме блокировки, поэтому следует применять тайм-аут. Пользователи, ожидающие очереди в одном списке, образуют группу пользователей, в которой каждое сообщение потребляется только одним пользователем. Список, как структура данных Redis, может сохраняться на диске.
Для решения ограничений двух вышеупомянутых методов используется потоковая передача. Пользователи выбирают, откуда читать сообщения: «$» — для новых сообщений, «<id>» — для определенного идентификатора сообщения или «0-0» — для чтения с самого начала.
Подводя итог вышеизложенному, можно сказать, что очереди сообщений с базами данных и в Redis просты в обслуживании. Если они не могут удовлетворить наши потребности, то лучше использовать специальные продукты для организации очередей сообщений. Далее мы сравним два популярных варианта.
RabbitMQ в сравнении с Kafka
Крупным компаниям, которым необходимы надежные, масштабируемые и удобные в обслуживании системы, следует оценить продукты для организации очередей сообщений по следующим критериям
- Функциональность
- Производительность
- Масштабируемость
- Экосистема
На схеме ниже приведено сравнение двух стандартных продуктов для организации очереди сообщений: RabbitMQ и Kafka.

Как они работают
RabbitMQ работает как промежуточный слой для обмена сообщениями — он отправляет сообщения пользователям, а затем удаляет их после подтверждения. Это позволяет избежать скоплений сообщений, которые RabbitMQ считает проблематичными.
Kafka изначально создавался для массовой обработки журналов. Он сохраняет сообщения до истечения срока действия и позволяет пользователям получать сообщения в удобном для них темпе.
Языки и API-интерфейсы
RabbitMQ написан на Erlang, что затрудняет изменение основного кода. Однако он предлагает поддержку полнофункциональных API-интерфейсов и библиотек.
Kafka использует Scala и Java, но также имеет клиентские библиотеки и API-интерфейсы для популярных языков, таких как Python, Ruby и Node.js.
Производительность и масштабируемость
RabbitMQ обрабатывает десятки тысяч сообщений в секунду. Даже на более качественном оборудовании пропускная способность не намного выше.
Kafka может обрабатывать миллионы сообщений в секунду с высокой масштабируемостью.
Экосистема
Во многих современных приложениях для обработки больших наборов данных и потоковой передачи Kafka встроен по умолчанию. И вполне естественно применять его для таких вариантов использования.
Варианты использования очереди сообщений
Теперь, когда мы рассмотрели особенности различных очередей сообщений, давайте рассмотрим на нескольких примерах, как выбрать подходящий продукт.
Обработка и анализ журналов
Для сайта электронной коммерции с такими сервисами, как корзина для покупок, заказы и платежи, нам необходимо анализировать журналы для изучения заказов клиентов.
На схеме ниже показана типичная архитектура, использующая стек ELK:
- ElasticSearch — индексирует журналы для полнотекстового поиска.
- LogStash — агент сбора журналов
- Kibana — пользовательский интерфейс для поиска и визуализации журналов
- Кафка — распределенная очередь сообщений
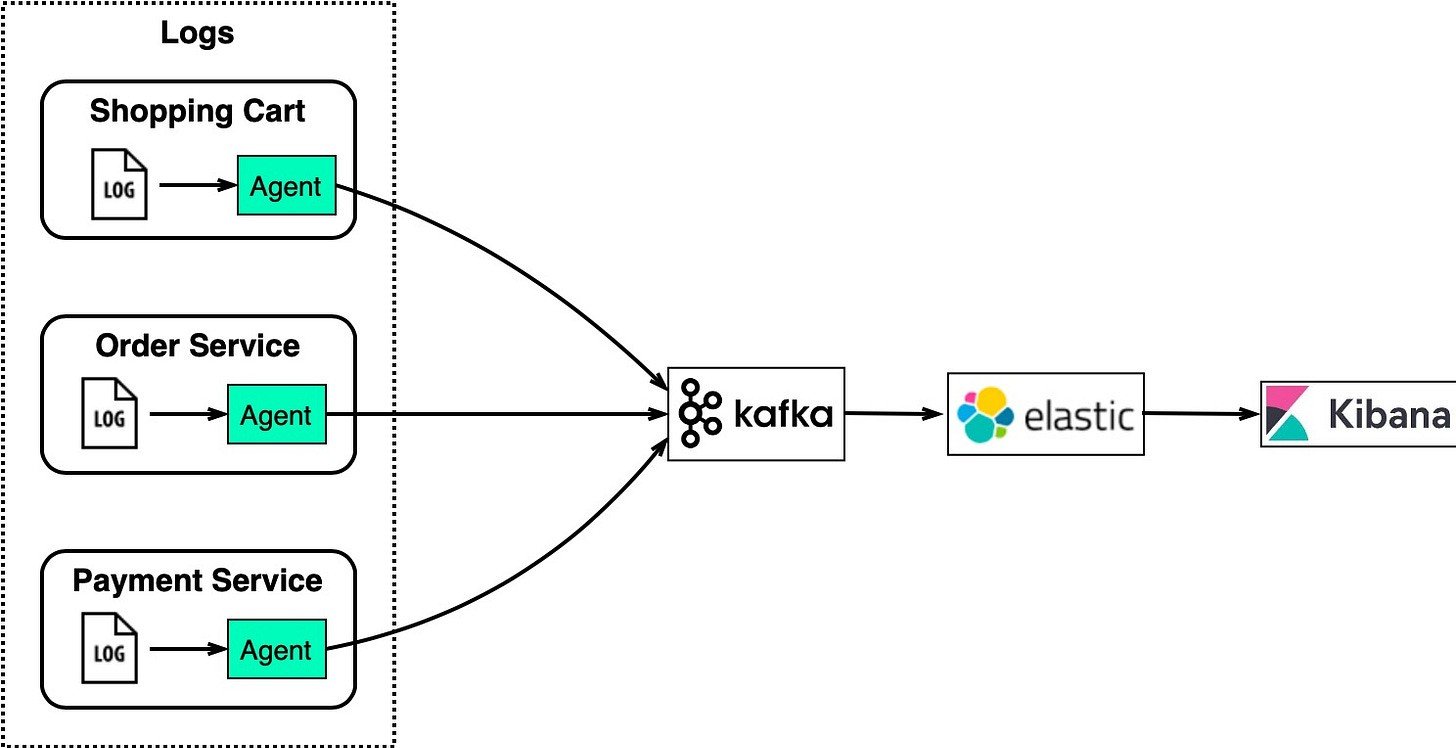
Эта архитектура хорошо работает для крупных сайтов электронной коммерции с множеством экземпляров сервисов.
Kafka эффективно собирает потоки журналов из каждого экземпляра. ElasticSearch использует журналы Kafka и индексирует их. Kibana предоставляет пользовательский интерфейс для поиска и визуализации в дополнение к ElasticSearch.
Kafka обрабатывает большой объем собранных журналов, ElasticSearch индексирует журналы для быстрого текстового поиска, а Kibana позволяет пользователям визуально анализировать заказы, пользователей, продукты и т. д.
Потоковая передача данных для рекомендаций
Сайты электронной коммерции, такие как Amazon, используют информацию о прошлом поведении и похожих пользователях для расчета рекомендаций по продуктам.
На рисунке ниже показано, как это работает:
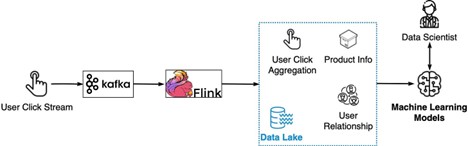
Клики пользователей на рекомендации по продукту указывают на удовлетворенность.
-
Сведения о посещениях собираются Kafka.
-
Flink агрегирует сведения о посещениях.
-
Агрегированные данные объединяются с информацией о продукте и взаимоотношениями пользователей в озере данных.
-
Данные используются для обучения моделей машинного обучения для улучшения рекомендаций.
Таким образом, Kafka передает необработанные сведения о посещениях, Flink обрабатывает их, а обучение моделей использует агрегированные данные из озера данных. Это позволяет постоянно повышать актуальность рекомендаций для каждого пользователя.
Системный мониторинг и оповещение
Подобно системе анализа журналов, нам необходимо собирать метрики системы для мониторинга и устранения неисправностей. Разница в том, что метрики представляют собой структурированные данные, а журналы — это неструктурированный текст.
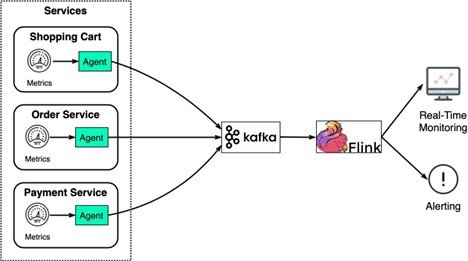
Архитектура такова: данные метрик отправляются в Kafka и агрегируются во Flink. Агрегированные данные используются панелью мониторинга в реальном времени и системой оповещения (например, PagerDuty).
-
Уровень узла: использование ЦП, использование памяти, емкость диска, использование подкачки, ввод-вывод, состояние сети.
-
Уровень процесса: идентификатор процесса, потоки, дескрипторы открытых файлов.
-
Уровень приложения: пропускная способность, задержка и т. д.
Это обеспечивает полное представление наблюдаемых объектов для всей системы.
Задержанные сообщения
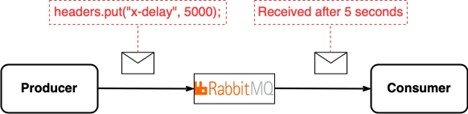
Иногда в распределенной среде нам требуется отложить доставку сообщений.
Пользователи Kafka получают сообщения сразу же. Задержанная доставка по умолчанию не поддерживается.
RabbitMQ поддерживает задержку сообщений путем установки в сообщении специального заголовка.
Если Kafka уже используется, но нам нужно задержать некоторые сообщения, например уведомления по электронной почте, добавление RabbitMQ может быть лишним.
Но в случае интенсивного использования задержек пользовательская настройка очереди с задержкой в Kafka неэффективна по сравнению с использованием встроенной функции задержки RabbitMQ. Выбор зависит от существующего комплекта технологий и того, насколько распространены в архитектуре задержанные сообщения.
Отслеживание измененных данных
Система отслеживания измененных данных (CDC) передает изменения базы данных в другие системы для репликации или обновления кэша/индекса.
CDC обычно моделируется как поток событий. CDC работает следующим образом: наблюдает за журналами транзакций базы данных и передает изменения в Kafka. Следующие в технологической цепочке системы, такие как поиск, кэши и реплики, обновляются из Kafka.
Например, на схеме ниже показано, как журнал транзакций передается в Kafka и принимается ElasticSearch, Redis и базами данных-получателями.

Такая архитектура обеспечивает обновление следующих в технологической цепочке систем и упрощает горизонтальную масштабируемость. Например, чтобы добавить реплику для «тяжелых» запросов, сделайте снимок, а затем используйте соединитель Kafka для потоковой передачи изменений.
CDC с Kafka является гибким: реплики остаются синхронизированными, поиск и обновление кэша, а также масштабирование пользователей не вызывают затруднений.
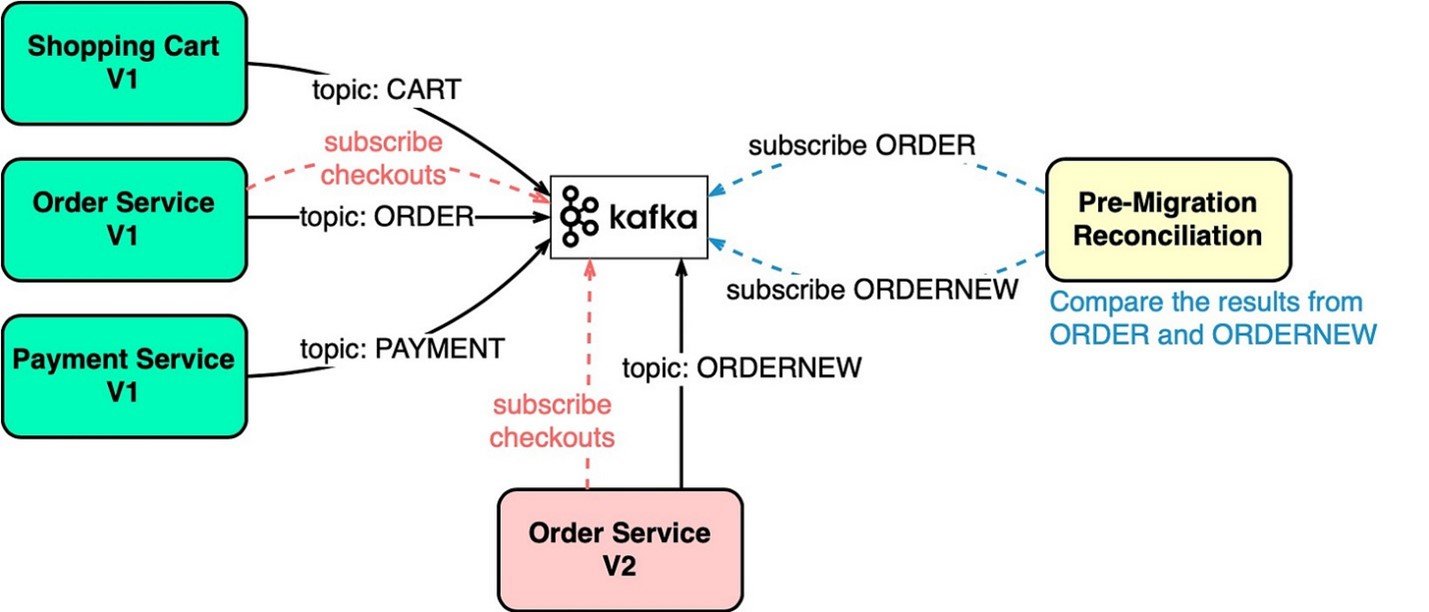
Миграция приложений
Обновление устаревших сервисов представляет собой сложную задачу — старые языки, сложная логика, отсутствие тестов. Напрямую заменять эти устаревшие сервисы рискованно. Однако мы можем снизить риск, используя ПО промежуточного слоя для обмена сообщениями.
Например, чтобы обновить службу заказов, показанную на схеме ниже, мы обновляем устаревшую службу заказов, чтобы она использовала входные данные из Kafka, и записываем результат в раздел ORDER. Служба новых заказов использует те же входные данные и записывает результат в раздел ORDERNEW. Сервис сверки сравнивает ORDER и ORDERNEW. Если они идентичны, новый сервис проходит тестирование.